掛け算を imul 命令を使わずに高速に計算する (x86/x64)
x86/x64 には掛け算命令(mul, imul)がありますが、あえてほかの命令を使って掛け算と同等の処理を行うことがあります。
たとえば、x64 の rax レジスタの値を 5 倍するのに、imul rax, rax, 5 ではなく、lea rax, QWORD PTR [rax+rax*4] とすることがあります。このほうが高速だからです。
ほかの倍数についても見てみましょう。
動作確認環境
- Windows 11 Home 24H2
- Visual Studio Community 2022 (Visual C++)
掛け算命令を使わずに 5 倍を計算
上記の 5 倍の例ですが、次のように引数を 5 倍する C 言語の関数を書き、
__int64 mul5(__int64 i)
{
return i * 5;
}Visual C++ x64 版でコンパイルし(「/c」はコンパイルのみでリンクはしない、「/O2」は速度最適化、「/FAs」はアセンブリリストを出力、の意味)、
C:\tmp> cl /c /O2 /FAs mul.c
Microsoft(R) C/C++ Optimizing Compiler Version 19.43.34810 for x64
......生成されたアセンブリリストを見ると、
C:\tmp> type mul.asm
......
lea rax, QWORD PTR [rcx+rcx*4]
......掛け算の imul 命令ではなく、実効アドレスロードの lea rax, QWORD PTR [rcx+rcx*4] 命令で 5 倍の計算をしていることがわかります。rcx レジスタの値に rcx レジスタの値を 4 倍した値を加算した結果を rax レジスタにセットしています。要するに rax = rcx + rcx * 4 です。
被乗数が rcx レジスタで、積が rax レジスタなのは、x64 呼び出し規約に従っているためです(参考文献 [1])。被乗数も rax レジスタにしたい場合は、引数ではなく関数の戻り値から取ってくるとよいでしょう。
たとえば次のソースをコンパイルしてアセンブリリストを見ると、
__int64 fn();
__int64 mul5()
{
return fn() * 5;
}被乗数が rax レジスタになります。
C:\tmp> type mul.asm
......
lea rax, QWORD PTR [rax+rax*4]
......2 ~ 16 倍の掛け算の結果
この方法で、2 倍 ~ 16 倍の掛け算についてコンパイラの出力を調べました。結果を以下に示します。
| 乗数 | 被乗数 が rcx の場合 | 被乗数 が rax の場合 | コメント |
|---|---|---|---|
| 2 | lea rax, QWORD PTR [rcx+rcx] | add rax, rax | |
| 3 | lea rax, QWORD PTR [rcx+rcx*2] | lea rax, QWORD PTR [rax+rax*2] | |
| 4 | lea rax, QWORD PTR [rcx*4] | shl rax, 2 | |
| 5 | lea rax, QWORD PTR [rcx+rcx*4] | lea rax, QWORD PTR [rax+rax*4] | |
| 6 | lea rax, QWORD PTR [rcx+rcx*2] add rax, rax | lea rax, QWORD PTR [rax+rax*2] add rax, rax | |
| 7 | imul rax, rcx, 7 | imul rax, rax, 7 | 工夫なし |
| 8 | lea rax, QWORD PTR [rcx*8] | shl rax, 3 | |
| 9 | lea rax, QWORD PTR [rcx+rcx*8] | lea rax, QWORD PTR [rax+rax*8] | |
| 10 | lea rax, QWORD PTR [rcx+rcx*4] add rax, rax | lea rax, QWORD PTR [rax+rax*4] add rax, rax | |
| 11 | imul rax, rcx, 11 | imul rax, rax, 11 | 工夫なし |
| 12 | lea rax, QWORD PTR [rcx+rcx*2] shl rax, 2 | lea rax, QWORD PTR [rax+rax*2] shl rax, 2 | |
| 13 | imul rax, rcx, 13 | imul rax, rax, 13 | 工夫なし |
| 14 | imul rax, rcx, 14 | imul rax, rax, 14 | 工夫なし |
| 15 | imul rax, rcx, 15 | imul rax, rax, 15 | 工夫なし |
| 16 | shl rcx, 4 mov rax, rcx | shl rax, 4 |
一部を除き、掛け算の imul ではなく実効アドレスロードの lea や左シフトの shl や足し算の add を使って倍数を計算しています。3 倍、5 倍、9 倍が lea 命令ひとつで処理できるのがおもしろいですね。
本当に imul より lea のほうが速いのか
そもそもですが、本当に imul より lea のほうが速いのかという疑問があります。実験してみましょう。
最近の CPU は複雑で、条件によって動作が変わるため測定が難しいですが、今回は以下の x64 アセンブリ言語プログラムで試してみます。
EXTERN GetTickCount: PROC
EXTERN printf: PROC
.data
PRINTFORMAT BYTE "time: %ld ms ", 0Dh, 0Ah, 0
.code
main PROC
;------ スタックの確保と整列
sub rsp, 28h
;------ 開始時刻の取得
call GetTickCount
mov r10d, eax
;------ 10 億回の繰り返し
mov rcx, 1000000000
L_Repeat:
; lea 命令で 5 倍
; lea rax, QWORD PTR [rax+rax*4]
; lea rax, QWORD PTR [rax+rax*4]
; lea rax, QWORD PTR [rax+rax*4]
; lea rax, QWORD PTR [rax+rax*4]
; lea rax, QWORD PTR [rax+rax*4]
; lea rax, QWORD PTR [rax+rax*4]
; lea rax, QWORD PTR [rax+rax*4]
; lea rax, QWORD PTR [rax+rax*4]
; lea rax, QWORD PTR [rax+rax*4]
; lea rax, QWORD PTR [rax+rax*4]
; imul 命令で 5 倍
; imul rax, rax, 5
; imul rax, rax, 5
; imul rax, rax, 5
; imul rax, rax, 5
; imul rax, rax, 5
; imul rax, rax, 5
; imul rax, rax, 5
; imul rax, rax, 5
; imul rax, rax, 5
; imul rax, rax, 5
dec rcx
jnz L_Repeat
;------ 終了時刻の取得
call GetTickCount
;------ 所要時間を表示
sub eax, r10d
mov edx, eax
lea rcx, PRINTFORMAT
call printf
;------ 戻り値の設定
xor eax, eax
;------ スタックの解放
add rsp, 28h
ret
main ENDP
ENDMASM でアセンブルします。
C:\tmp> ml64 test.asm /link user32.lib msvcrt.lib legacy_stdio_definitions.lib
Microsoft (R) Macro Assembler (x64) Version 14.43.34810.0
......実行します。
C:\tmp> test.exe
time: 265 ms単純な 10 億回ループで、265 ms でした。
次に、コメントアウトしてある「lea 命令で 5 倍」直下の 10 個の lea 命令を有効にして再コンパイル、再実行します。
C:\tmp> ml64 test.asm /link user32.lib msvcrt.lib legacy_stdio_definitions.lib
......
C:\tmp> test.exe
time: 2641 ms「この時間 – 単純ループの時間」を、「lea 命令で 5 倍」命令の 100 億回の実行時間とします。2641 – 265 = 2376 ms です。
続いて、「imul 命令で 5 倍」直下の 10 個の imul 命令のほうを有効にして再コンパイル、再実行します。
C:\tmp> ml64 test.asm /link user32.lib msvcrt.lib legacy_stdio_definitions.lib
......
C:\tmp> test.exe
time: 8250 ms「この時間 – 単純ループの時間」を、「imul 命令で 5 倍」命令の 100 億回の実行時間とします。8250 – 265 = 7985 ms です。
このようにして、被乗数が rax レジスタの場合の他の乗数についても測定しました。結果を以下に示します。グラフが長いほど所要時間が長い、つまり遅いことを意味します。
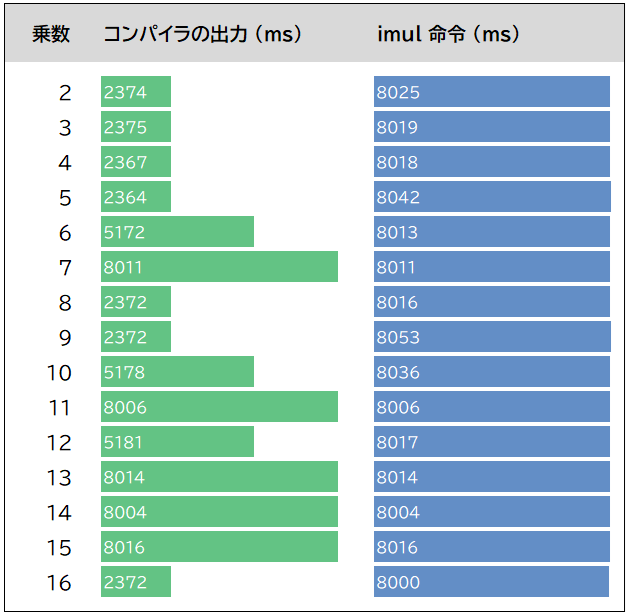
所要時間の比率は、lea や shl や add が 1 なのに対し、imul は 3 という結果になりました。
なお、時間は 10 回測定して平均を算出しています。CPU は少し古い Core i5-8265U です。
おわりに
掛け算を imul ではなく lea や shl や add で計算する例について見てきました。
昔に比べると掛け算命令はずいぶん速くなりましたが、それでもまだ、可能であれば、実効アドレスロードやシフト演算や足し算で計算したほうが速いようです。
追記
その後、インテルのドキュメント [3] に次の表があることに気付きました。
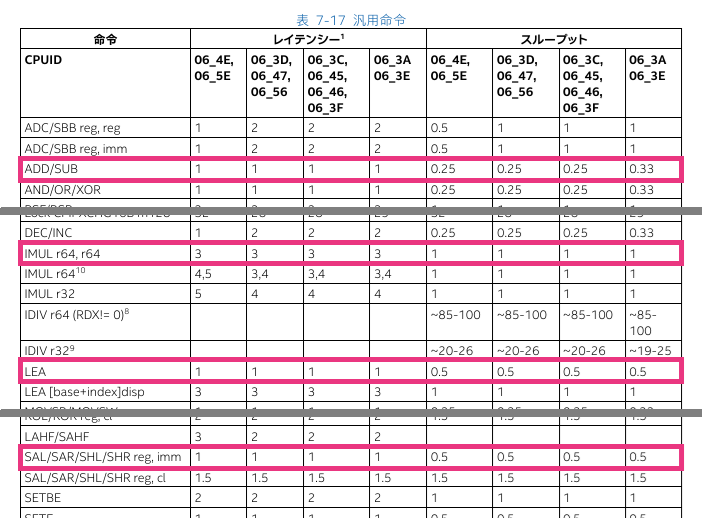
レイテンシー(命令を構成しているすべてのマイクロオペレーションの実行が実行コアで完了するのに要するクロックサイクル数)を見ると、
- add : 1
- lea(2 引数以下) : 1
- shl : 1
- imul : 3
となっており、測定結果と一致します。imul はほかの命令の 3 倍であり、また、計算には rax レジスタのみを使っており前の命令が終わらないと次の命令が実行できないからです。
一方、imul のスループット(発行ポートが同じ種類の命令を再度受け入れられるようになるまで待たなければならないクロックサイクル数)は、
- imul : 1
となっています。前後に依存関係がなければ 1 サイクルで実行できることを意味し、実際、次のコードの箇所を、
......
imul rax, rax, 5
imul rax, rax, 5
imul rax, rax, 5
imul rax, rax, 5
imul rax, rax, 5
imul rax, rax, 5
imul rax, rax, 5
imul rax, rax, 5
imul rax, rax, 5
imul rax, rax, 5
......次のように書き換えても、実行時間は同じ約 8000 ms でした。
......
imul rax, rax, 5
imul r8, r8, 5
imul r9, r9, 5
imul rax, rax, 5
imul r8, r8, 5
imul r9, r9, 5
imul rax, rax, 5
imul r8, r8, 5
imul r9, r9, 5
imul rax, rax, 5
imul r8, r8, 5
imul r9, r9, 5
imul rax, rax, 5
imul r8, r8, 5
imul r9, r9, 5
imul rax, rax, 5
imul r8, r8, 5
imul r9, r9, 5
imul rax, rax, 5
imul r8, r8, 5
imul r9, r9, 5
imul rax, rax, 5
imul r8, r8, 5
imul r9, r9, 5
imul rax, rax, 5
imul r8, r8, 5
imul r9, r9, 5
imul rax, rax, 5
imul r8, r8, 5
imul r9, r9, 5
......したがって、実際のプログラムでは上の棒グラフのイメージよりも速く imul 命令が処理されることが期待できます。
参考文献
[1] やや低レイヤー研究所「x64 呼び出し規約をわかりやすく説明してみる (Windows)」
https://yaya.lsv.jp/x64-calling-convention/
[2] やや低レイヤー研究所「x64 アセンブリ言語で、Windows API や C 言語のライブラリを呼び出す .exe, .lib, .dll を開発する (Windows, MASM)」
https://yaya.lsv.jp/masm_x64_sample/
[3] インテル「インテル (R) 64 および IA-32 アーキテクチャー 最適化リファレンス・マニュアル参考訳 Volume 2」2024
https://www.isus.jp/wp-content/uploads/pdf/64-ia-32-architectures-optimization-manual-vol2_JA.pdf