割り算の商と余りを同時に計算する(x86, x64, C言語)
「割り算の商と余りを同時に計算する」と書きましたが、特別な方法を使うわけではありません。x86/x64 の割り算命令は商と余り(剰余)の両方を同時に計算してくれます。
動作確認環境
- Windows 11 Home 24H2
- Visual Studio Community 2022 (Visual C++)
x86/x64 の割り算命令
x86/x64 アセンブリ言語の割り算命令は div(符号なし)または idiv(符号付き)です。
Intel のドキュメントから div と idiv の表を引用します。
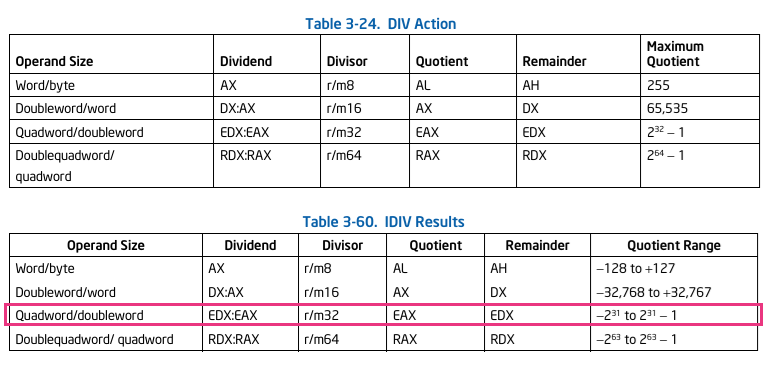
赤枠で囲った行は次の意味になります。
Quadword/doubleword、言い換えると QWORD(64bit) / DWORD(32bit) の割り算について :
・ 割られる数 = edx と eax レジスタの組み合わせで指定 (64bit)
・ 割る数 = レジスタやメモリアドレスで指定 (32bit)
↓ idiv 命令
・ 商 = eax レジスタに格納される (32bit)
・ 余り = edx レジスタに格納される (32bit)00000001:234500EF(h) / 00001000(h) の符号付き割り算を行う場合、割られる数 00000001:234500EF(h) を edx:eax レジスタにセットし、割る数 00001000(h) をたとえば ecx レジスタにセットし、idiv 命令を実行します。
mov edx, 00000001h ; 割られる数(上位)
mov eax, 234500EFh ; 割られる数(下位)
mov ecx, 00001000h ; 割る数
idiv ecx ; 割り算すると、商 00123450(h) が eax レジスタに 、余り 000000EF(h) が edx レジスタに格納されます。
割り算を行い商と余りを表示する、x86 アセンブリ言語プログラムを書いてみます。画面表示には C ランタイムライブラリの printf 関数を利用します。
.686
.model flat
EXTERN _printf: PROC
.data
PRINTFORMAT BYTE "q=%08X(h), r=%08X(h)", 0Dh, 0Ah, 0
.code
_main PROC
; push ebp
; mov ebp, esp
;------ 割り算
mov edx, 00000001h ; 割られる数(上位)
mov eax, 234500EFh ; 割られる数(下位)
mov ecx, 00001000h ; 割る数
idiv ecx ; 割り算
; ここで、商 00123450(h) は eax レジスタに 、
; 余り 000000EF(h) は edx レジスタに格納される。
;------ 結果の表示
push edx ; 第 3 引数(余り)
push eax ; 第 2 引数(商)
push OFFSET PRINTFORMAT ; 第 1 引数(フォーマット)
call _printf ; printf 関数呼び出し
add esp, 12 ; スタックのクリーンアップ
; mov esp, ebp
; pop ebp
ret
_main ENDP
ENDx86 Native Tools Command Prompt for VS 2022 のコマンドプロンプトを開き、
MASM(マイクロソフトマクロアセンブラー)の ml コマンドでアセンブルします。
C:\tmp> ml test1.asm /link msvcrt.lib ucrt.lib legacy_stdio_definitions.lib /subsystem:console
Microsoft (R) Macro Assembler Version 14.39.33523.0
Copyright (C) Microsoft Corporation. All rights reserved.
Assembling: test1.asm
Microsoft (R) Incremental Linker Version 14.39.33523.0
Copyright (C) Microsoft Corporation. All rights reserved.
/OUT:test1.exe
test1.obj
msvcrt.lib
ucrt.lib
legacy_stdio_definitions.lib
/subsystem:console生成された test1.exe ファイルを実行します。
C:\tmp> test1.exe
q=00123450(h), r=000000EF(h)予想通り、idiv 命令により商と余りが同時に計算され、結果が表示されました。
商が範囲内に収まらないと例外発生
少し話が変わりますが、いま計算した
- 00000001:234500EF(h) / 00001000(h) = 00123450(h) 余り 000000EF(h)
は、
- 割られる数 64bit / 割る数 32bit = 商 32bit 余り 32bit
のビット長に収まっています。しかし、割る数を 1 にすると
- 00000001:234500EF(h) / 00000001(h) = 00000001:234500EF(h) 余り 00000000(h)
となり、商が eax レジスタの 32bit を超えてしまいます。この計算をするとどうなるのか気になるので試してみます。
さきほどのプログラムを書き換え、割る数を 1 にします。
......
;------ 割り算
mov edx, 00000001h ; 割られる数(上位)
mov eax, 234500EFh ; 割られる数(下位)
mov ecx, 00000001h ; 割る数 ★ 1 に変更
idiv ecx ; 割り算
......アセンブルします。
C:\tmp> ml test2.asm /link msvcrt.lib ucrt.lib legacy_stdio_definitions.lib /subsystem:console実行します。
C:\tmp> test2.exe手元の PC は例外が発生すると WinDbg が起動するよう設定してあり(WinDbg -I)、test2.exe を実行した瞬間に WinDbg が起動しました。
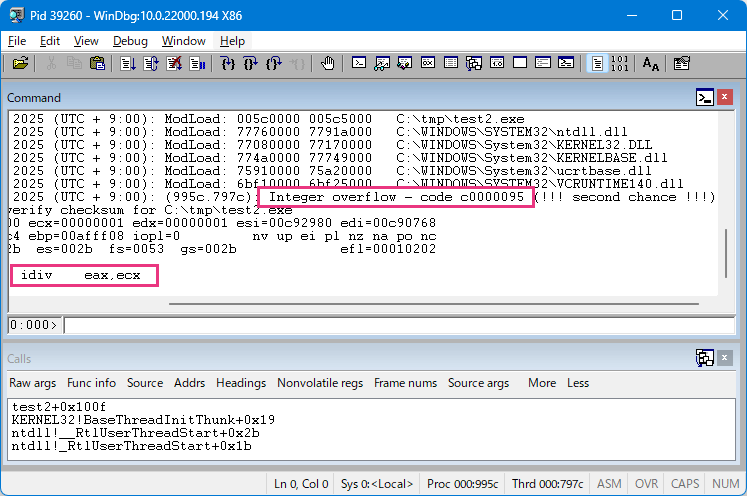
WinDbg の画面は「idiv eax, ecx」命令で「Integer overflow – code c0000095」の例外が発生したことを示しています。idiv 命令は、ゼロ除算のときだけでなく、商が既定の範囲を超えた場合も例外が発生するようです。
改めて Intel のドキュメントを見ると、idiv 命令の動作の説明にその旨書いてありました(#DE, Divide error)。
......
IF OperandSize = 32 (* Quadword/doubleword operation *)
temp := EDX:EAX / SRC; (* Signed division *)
IF (temp > 7FFFFFFFH) or (temp < 80000000H)
(* If a positive result is greater than 7FFFFFFFH
or a negative result is less than 80000000H *)
THEN
#DE; (* Divide error *)
ELSE
EAX := temp;
EDX := EDXE:AX SignedModulus SRC;
FI;
FI;
......C 言語の「/」と「%」をひとつの idiv 命令にできる?
C 言語では、「/」が商を求める、「%」が余りを求める演算子です。「/」と「%」を連続して使うと、コンパイラによってひとつの idiv 命令にまとめられるのでしょうか。試してみます。
コマンドライン引数として割られる数と割る数を受け取り、商と余りを計算・表示する C 言語のプログラム「test3.c」を書きます。エラーチェックは省略しています。
#include <stdio.h>
int main(int argc, char *argv[])
{
int divd, divr, q, r;
divd = atoi(argv[1]); // 割られる数
divr = atoi(argv[2]); // 割る数
q = divd / divr; // 商
r = divd % divr; // 余り
printf("q=%d, r=%d\n", q, r);
return 0;
}x86 Native Tools Command Prompt for VS 2022 のコマンドプロンプトを開き、cl コマンドでビルドします。「/Od」は最適化なし、「/FAs」はアセンブリリストを生成、の意味です。
C:\tmp> cl /Od /FAs test3.c生成されたアセンブリリストを見てみます。
......
; 10 : q = divd / divr; // 商
mov eax, DWORD PTR _divd$[ebp]
cdq
idiv DWORD PTR _divr$[ebp]
mov DWORD PTR _q$[ebp], eax
; 11 : r = divd % divr; // 余り
mov eax, DWORD PTR _divd$[ebp]
cdq
idiv DWORD PTR _divr$[ebp]
mov DWORD PTR _r$[ebp], edx
......「/」に 1 回、「%」にもう 1 回、合わせて 2 回、idiv 命令が呼び出されています。最適化なしでビルドしたので当然でしょう。
次に速度最適化「/O2」のオプションを付けてビルドしてみます。
C:\tmp> cl /O2 /FAs test3.c生成されたアセンブリリストを見てみます。
......
; 10 : q = divd / divr; // 商
; 11 : r = divd % divr; // 余り
mov eax, edi
cdq
idiv ecx
......「/」と「%」の 2 つの演算が、ひとつの idiv 命令にまとめられました。期待通りです。
ところが、プログラムを少し変えると結果が違ってきます。以下は、割られる数と割る数の代入に atoi 関数ではなく scanf 関数を使った「test4.c」です。
#include <stdio.h>
int main(int argc, char *argv[])
{
int divd, divr, q, r;
scanf("%d", &divd); // 割られる数
scanf("%d", &divr); // 割る数
q = divd / divr; // 商
r = divd % divr; // 余り
printf("q=%d, r=%d\n", q, r);
return 0;
}速度最適化「/O2」のオプションを付けてビルドします。
C:\tmp> cl /O2 /FAs test4.c生成されたアセンブリリストを見てみます。
......
; 10 : q = divd / divr; // 商
; 11 : r = divd % divr; // 余り
mov eax, DWORD PTR _divd$[esp+24]
cdq
idiv DWORD PTR _divr$[esp+24]
mov eax, DWORD PTR _divd$[esp+24]
; 12 :
; 13 : printf("q=%d, r=%d\n", q, r);
push edx
cdq
idiv DWORD PTR _divr$[esp+28]
push eax
push OFFSET ??_C@_0M@CMCCKACO@q?$DN?$CFd?0?5r?$DN?$CFd?6@
call _printf
......最適化がうまくいっていないのか、idiv 命令が無駄に 2 回呼び出されています。
連続する「/」と「%」がひとつの idiv 命令にまとめられるかどうかは文脈によりけりで生成されたコードを見てみないとわからない、と言えそうです。
C 言語の div 関数はひとつの idiv 命令になる?
C 言語のライブラリには商と余りを同時に求める div 関数があります。
書式は次の通りです。引数に割られる数と割る数を指定します。
#include <stdlib.h>
div_t div(
int numer,
int denom
);計算結果は div_t 型の構造体で返ってきます。
typedef struct _div_t
{
int quot;
int rem;
} div_t;この div 関数を使えば、商と余りの計算がひとつの idiv 命令にまとめられるのでしょうか。
先の「test3.c」をベースに、「/」や「%」演算子の代わりに div 関数を使った「test5.c」を書いてみます。
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
int divd, divr;
div_t ans;
divd = atoi(argv[1]); // 割られる数
divr = atoi(argv[2]); // 割る数
ans = div(divd, divr); // 割り算をして商と余りを構造体で返却
printf("q=%d, r=%d\n", ans.quot, ans.rem);
return 0;
}最適化なしでビルドします。「/Zi」は「デバッグ情報を生成」の意味です(.exe ファイルの逆アセンブルを見やすくするために付加)。
c:\tmp> cl /Od /FAs /Zi test5.c生成されたアセンブリリストと .exe の逆アセンブル結果 (dumpbin /disasm test5.exe) から div 関数の処理を抜き出したものが以下です。
......
; 12 : ans = div(divd, divr); // 割り算をして商と余りを構造体で返却
mov eax, DWORD PTR _divr$[ebp]
push eax
mov ecx, DWORD PTR _divd$[ebp]
push ecx
call _div
add esp, 8
mov DWORD PTR _ans$[ebp], eax
mov DWORD PTR _ans$[ebp+4], edx
......
_div:
mov edi,edi
push ebp
mov ebp,esp
mov eax,dword ptr [ebp+8]
cdq
idiv eax,dword ptr [ebp+0Ch]
pop ebp
ret
......期待通り、div 関数の実体は、idiv 命令 1 回で商と余りの計算を済ませていました。ただし、関数呼び出しのオーバーヘッド(call _div)が気になります。
速度最適化を指定してビルドするとどうなるでしょうか。
c:\tmp> cl /O2 /FAs test5.cアセンブリリストの抜粋です。
......
; 12 : ans = div(divd, divr); // 割り算をして商と余りを構造体で返却
mov eax, edi
cdq
idiv ecx
......div 関数の呼び出しがインライン展開され、その場で idiv 命令が発行されるようになりました。
しかし改めて見てみると、「/」と「%」を使った「test3.c」も、div 関数を使った「test5.c」も、速度最適化 ON で生成されるコードは同じであり、あまり馴染みのない div 関数を使うメリットが感じられません。
今度は「test4.c」をベースに、「/」や「%」演算子の代わりに div 関数を使った「test6.c」を書いてみます。
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
int divd, divr;
div_t ans;
scanf("%d", &divd); // 割られる数
scanf("%d", &divr); // 割る数
ans = div(divd, divr); // 割り算をして商と余りを構造体で返却
printf("q=%d, r=%d\n", ans.quot, ans.rem);
return 0;
}速度最適化を指定してビルドします。
c:\tmp> cl /O2 /FAs test6.c生成されたアセンブリリストの抜粋です。
......
; 11 :
; 12 : ans = div(divd, divr); // 割り算をして商と余りを構造体で返却
mov eax, DWORD PTR _divd$[esp+28]
cdq
idiv DWORD PTR _divr$[esp+28]
mov edi, eax
mov eax, DWORD PTR _divd$[esp+28]
cdq
idiv DWORD PTR _divr$[esp+28]
; 13 :
; 14 : printf("q=%d, r=%d\n", ans.quot, ans.rem);
push edx
push edi
push OFFSET ??_C@_0M@CMCCKACO@q?$DN?$CFd?0?5r?$DN?$CFd?6@
call _printf
add esp, 28 ; 0000001cH
......今度はなぜか、C 言語のひとつの div 関数がアセンブリ言語の 2 つの idiv 命令に分割されてしまいました。
Visual C++ の _div64 組み込み関数は idiv 命令と同じ?
Visual C++ のライブラリには、div 関数によく似た _div64 関数があります。組み込み関数 (intrinsics) と呼ばれるマシン語に直結するタイプの関数であり、書式は次の通りです。
#include <intrin.h>
int _div64(
__int64 dividend,
int divisor,
int* remainder
);先の「test3.c」をベースに、「/」や「%」の代わりに _div64 関数を使った「test7.c」を書いてみます。
#include <stdio.h>
#include <intrin.h>
int main(int argc, char *argv[])
{
__int64 divd;
int divr, q, r;
divd = (__int64)atoi(argv[1]); // 割られる数
divr = atoi(argv[2]); // 割る数
q = _div64(divd, divr, &r); // 組み込み関数で商と余りを計算
printf("q=%d, r=%d\n", q, r);
return 0;
}最適化なしでビルドします。
c:\tmp> cl /Od /FAs test7.c生成されたアセンブリリストの抜粋です。
......
; 12 : q = _div64(divd, divr, &r); // 組み込み関数で商と余りを計算
mov eax, DWORD PTR _divd$[ebp]
mov edx, DWORD PTR _divd$[ebp+4]
idiv DWORD PTR _divr$[ebp]
mov DWORD PTR _r$[ebp], edx
mov DWORD PTR _q$[ebp], eax
......期待通り、idiv 命令はひとつだけです。関数呼び出しのオーバーヘッドもありません。コードは省略しますが、速度最適化を指定してビルドした場合も同様でした。
これまでどうしても div 命令が 2 回発行されてしまった scanf 関数を使ったバージョンはどうなるでしょうか。
先の「test4.c」をベースに、「/」や「%」の代わりに _div64 関数を使った「test8.c」を書きます。
#include <stdio.h>
#include <intrin.h>
int main(int argc, char *argv[])
{
__int64 divd;
int divr, q, r;
scanf("%lld", &divd); // 割られる数
scanf("%d", &divr); // 割る数
q = _div64(divd, divr, &r); // 組み込み関数で商と余りを計算
printf("q=%d, r=%d\n", q, r);
return 0;
}最適化なしでビルドします。
c:\tmp> cl /Od /FAs test8.c生成されたアセンブリリストの抜粋です。
; 12 : q = _div64(divd, divr, &r); // 組み込み関数で商と余りを計算
mov eax, DWORD PTR _divd$[ebp]
mov edx, DWORD PTR _divd$[ebp+4]
idiv DWORD PTR _divr$[ebp]
mov DWORD PTR _r$[ebp], edx
mov DWORD PTR _q$[ebp], eaxこちらも idiv 命令はひとつだけです。コードは省略しますが、速度最適化を指定してビルドした場合も同様でした。
結局、_div64 関数を使っておけば間違いなさそうです。
おわりに
割り算の商と余りを同時に計算する方法について見てきました。
今回試した範囲での結果をまとめます。
- x86/x64 の div 命令や idiv 命令は、商と余りを同時に計算できます。
- C 言語の「/」と「%」を使った 2 つの式を、最適化によりコンパイラが 1 つの idiv 命令にまとめてくれることがあります。まとめてくれないこともあります。
- C 言語の div 関数も、状況により、idiv 命令が 1 つになったり 2 つになったりします。
- Visual C++ の _div64 組み込み関数を使えば、idiv 命令は 1 回しか発行されず、安定的に高速に処理されます。ただし _div64 はマクロソフト固有の関数です。
参考文献
[1] Intel「Intel(R) 64 and IA-32 Architectures Software Developer’s Manual」, 2024