何もしない長い命令、マルチバイト NOP (x86/x64)
x86/x64 CPU には、何もしないマシン語「90」(16進数)が存在します。アセンブリ言語でいうと「NOP」です。
では 2 バイト以上を何もしない命令でふさぎたい場合は「90」を繰り返せばいいのかというと、それでも構いませんが、
- 2 バイトの何もしないマシン語「66 90」
- 3 バイトの何もしないマシン語「0F 1F 00」
- 4 バイトの何もしないマシン語「0F 1F 40 00」
- ……
といった専用の命令が存在します。
こうした何もしない長い命令「マルチバイト NOP」について調べてみます。
動作確認環境
- Windows 11 Home 21H2
- Visual Studio Community 2019
マルチバイト NOP
2 バイト以上の何もしない命令「マルチバイト NOP」は、隠しコマンドというわけではなく、インテルの開発者マニュアル [1] の「NOP」の項にも掲載されている公式の命令です。同書から抜粋して意訳します。
NOP - No Operation
これは何もしない命令です。
1 バイト NOP もマルチバイト NOP も、CPU の命令ストリームを流れますが、
EIP レジスタ(インストラクションポインタ)を進める以外何もしません。
マルチバイト NOP の推奨例を以下に示します。これらは 1 命令として処理されます。
長さ: マシン語 : アセンブリ言語
2 : 66 90 : 66 NOP
3 : 0F 1F 00 : NOP DWORD ptr [EAX]
4 : 0F 1F 40 00 : NOP DWORD ptr [EAX + 00H]
5 : 0F 1F 44 00 00 : NOP DWORD ptr [EAX + EAX*1 + 00H]
6 : 66 0F 1F 44 00 00 : 66 NOP DWORD ptr [EAX + EAX+1 + 00H]
7 : 0F 1F 80 00 00 00 00 : NOP DWORD ptr [EAX + 00000000H]
8 : 0F 1F 84 00 00 00 00 00 : NOP DWORD ptr [EAX + EAX*1 + 00000000H]
9 : 66 0F 1F 84 00 00 00 00 00 : 66 NOP DWORD ptr [EAX + EAX*1 + 00000000H]9 バイトまでのマルチバイト NOP が掲載されています。
NOP を繰り返すとそれだけ命令数が増えるのに対し、マルチバイト NOP はたとえ長くても 1 命令として処理されるとのことで、処理時間が短いことが期待できます。これがマルチバイト NOP の存在意義と考えられます。
マイクロソフトの定義ファイル
Visual Studio に含まれている「listing.inc」ファイルにも、マルチバイト NOP が定義されています。
......
npad macro size
if size eq 1
DB 90H
else
if size eq 2
DB 66H, 90H
else
if size eq 3
DB 0FH, 1FH, 00H
else
if size eq 4
DB 0FH, 1FH, 40H, 00H
else
if size eq 5
DB 0FH, 1FH, 44H, 00H, 00H
else
if size eq 6
DB 66H, 0FH, 1FH, 44H, 00H, 00H
else
if size eq 7
DB 0FH, 1FH, 80H, 00H, 00H, 00H, 00H
else
if size eq 8
DB 0FH, 1FH, 84H, 00H, 00H, 00H, 00H, 00H
else
if size eq 9
DB 66H, 0FH, 1FH, 84H, 00H, 00H, 00H, 00H, 00H
else
if size eq 10
DB 66H, 66H, 0FH, 1FH, 84H, 00H, 00H, 00H, 00H, 00H
else
if size eq 11
DB 66H, 66H, 66H, 0FH, 1FH, 84H, 00H, 00H, 00H, 00H, 00H
else
if size eq 12
DB 0FH, 1FH, 40H, 00H, 0FH, 1FH, 84H, 00H, 00H, 00H, 00H, 00H
else
if size eq 13
DB 0FH, 1FH, 40H, 00H, 66H, 0FH, 1FH, 84H, 00H, 00H, 00H, 00H, 00H
else
if size eq 14
DB 0FH, 1FH, 40H, 00H, 66H, 66H, 0FH, 1FH, 84H, 00H, 00H, 00H, 00H, 00H
else
if size eq 15
DB 0FH, 1FH, 40H, 00H, 66H, 66H, 66H, 0FH, 1FH, 84H, 00H, 00H, 00H, 00H, 00H
......15 バイトまで定義されていますが、よく見ると 12 バイト以上は短いマルチバイト NOP の組み合わせになっており、1 命令のマルチバイト NOP としては 11 バイトが最大長です。
本当にこんな「何もしない長い命令」が使えるのか試してみましょう。
x86 アセンブリ言語で次のプログラムを書きます。
.model flat, C
.code
_main PROC
db 66H, 66H, 66H, 0FH, 1FH, 84H, 00H, 00H, 00H, 00H, 00H ; ★ マシン語直接埋め込み
ret
_main ENDP
end「listing.inc」で定義されている npad マクロを使って書くこともできます。
include listing.inc
.model flat, C
.code
_main PROC
npad 11 ; ★ npad マクロを利用
ret
_main ENDP
endMASM でアセンブルします。
C:\tmp> ml 11nop.asm /link /subsystem:console /entry:_main
Microsoft (R) Macro Assembler Version 14.28.29913.0
......
/OUT:11nop.exe
11nop.obj
/subsystem:console
/entry:_main逆アセンブルしてみます。
C:\tmp> dumpbin /disasm 11nop.exe
......
00401000: 66 66 66 0F 1F 84 nop word ptr [eax+eax+00000000h]
00 00 00 00 00
0040100B: C3 ret
......確かに 11 バイトの命令として解釈されています。
実行します。
C:\tmp> 11nop.exe
C:\tmp>エラーは出ませんでした。「何もしない長い命令」が実行されたようです。
マルチバイト NOP は本当に速いのか
マルチバイト NOP は本当に速いのか、計測してみましょう。
次のひな型を用意します。二重ループで 1000 億回ループする x86 アセンブリ言語のプログラムです。
.model flat, C
.code
_main PROC
mov edi, 1000000
OuterLoop:
mov esi, 100000
InnerLoop:
; ★ ここに測定対象の命令を記述
sub esi, 1
jne SHORT InnerLoop
sub edi, 1
jne SHORT OuterLoop
ret
_main ENDP
endそして、「★ ここに測定対象の命令を記述」の箇所に「NOP の繰り返し」や「マルチバイト NOP」を記述し、実行時間を測定します。
CPU のモデルやクロック数によって異なるでしょうが、手元の PC での測定結果は次のようになりました。
【 NOP の繰り返し, 1000 億回 】
長さ: マシン語 : 所要時間(秒)
1 : 90 : 27
2 : 90 90 : 27
3 : 90 90 90 : 26
4 : 90 90 90 90 : 35
5 : 90 90 90 90 90 : 39
6 : 90 90 90 90 90 90 : 53
7 : 90 90 90 90 90 90 90 : 53
8 : 90 90 90 90 90 90 90 90 : 61
9 : 90 90 90 90 90 90 90 90 90 : 69
10 : 90 90 90 90 90 90 90 90 90 90 : 78
11 : 90 90 90 90 90 90 90 90 90 90 90 : 78
【 マルチバイト NOP, 1000 億回 】
長さ: マシン語 : 所要時間(秒)
1 : - : -
2 : 66 90 : 28
3 : 0F 1F 00 : 28
4 : 0F 1F 40 00 : 28
5 : 0F 1F 44 00 00 : 28
6 : 66 0F 1F 44 00 00 : 28
7 : 0F 1F 80 00 00 00 00 : 28
8 : 0F 1F 84 00 00 00 00 00 : 28
9 : 66 0F 1F 84 00 00 00 00 00 : 28
10 : 66 66 0F 1F 84 00 00 00 00 00 : 28
11 : 66 66 66 0F 1F 84 00 00 00 00 00 : 28グラフにします。
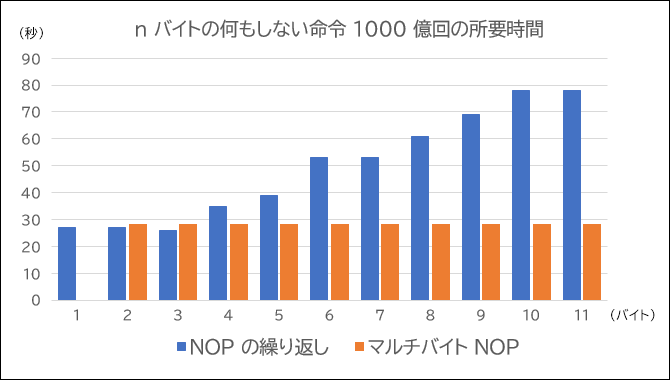
「NOP の繰り返し」は、バイト数が増えるにしたがって所要時間が増える傾向にありました。
一方、「マルチバイト NOP」は、バイト数が増えても所要時間が一定でした。
バイト数が長ければ長いほど「マルチバイト NOP」のほうが速くなると言えます。
ただし、3 バイト以下の場合に「NOP の繰り返し」のほうが微妙に速かったのは、誤差なのか CPU の設計によるものなのか確認できませんでした。
マルチバイト NOP はどこで使われているのか
マルチバイト NOP が役に立つケースは少なそうに思えますが、身近なところでは Visual C++ が生成するコードに使われています。
たとえば、二重ループで 1000 億回ループする C 言語プログラムを書きます(計算内容に意味はありません)。
#include <stdio.h>
int main()
{
int v = 0;
for (int i = 0; i < 1000000; i++)
{
v = v & i;
for (int j = 0; j < 100000; j++)
{
v = v | j;
}
}
printf("%d\n", v);
return 0;
}x64 の C コンパイラで、/O2 オプション(速度優先最適化)を付けてコンパイルします。
C:\tmp> cl /O2 nop_c.c
Microsoft(R) C/C++ Optimizing Compiler Version 19.28.29913 for x64
......
/out:nop_c.exe
nop_c.obj生成されたコードを見てみます。
C:\tmp> dumpbin /disasm nop_c.obj
......
main:
0000000000000000: 48 83 EC 28 sub rsp,28h
0000000000000004: 33 D2 xor edx,edx
0000000000000006: 45 33 C0 xor r8d,r8d
0000000000000009: 0F 1F 80 00 00 00 nop dword ptr [rax] ; ★ 7 バイト NOP
00
; ★ 外部ループのジャンプ先。直前の 7 バイト NOP により 16 バイト整列済み。
0000000000000010: 41 23 D0 and edx,r8d
0000000000000013: 33 C0 xor eax,eax
0000000000000015: 66 66 66 0F 1F 84 nop word ptr [rax+rax] ; ★ 11 バイト NOP
00 00 00 00 00
; ★ 内部ループのジャンプ先。直前の 11 バイト NOP により 16 バイト整列済み。
0000000000000020: 8D 48 01 lea ecx,[rax+1]
0000000000000023: 0B C8 or ecx,eax
0000000000000025: 83 C0 02 add eax,2
0000000000000028: 0B D1 or edx,ecx
000000000000002A: 3D A0 86 01 00 cmp eax,186A0h
000000000000002F: 7C EF jl 0000000000000020 ; ★ 0x20 に条件分岐
0000000000000031: 41 FF C0 inc r8d
0000000000000034: 41 81 F8 40 42 0F cmp r8d,0F4240h
00
000000000000003B: 7C D3 jl 0000000000000010 ; ★ 0x10 に条件分岐
......7 バイトと 11 バイトのマルチバイト NOP が使われています。これは、ジャンプ先アドレスを 16 バイト整列するための埋め草です。インテルの以前の最適化マニュアル [2] に「すべての分岐先は 16 バイト整列すべき(All branch targets should be 16-byte aligned.)」とあり、ループの高速化を期待して生成されたのでしょう。
しかし、実際に速くなるかは、さまざまな条件が絡んでくるので何とも言えません。上記プログラムの x64 アセンブラ版を作り、16 バイト整列ありとなしとで比較したところ、整列ありの 10 回平均が 26.24 秒、整列なしの 10 回平均が 26.18 秒となり、誤差の範囲内、あるいは微妙に遅くなっているように見えました。
参考文献
[1] Intel(R) 64 and IA-32 Architectures Software Developer’s Manual, December 2021.
https://www.intel.com/content/www/us/en/developer/articles/technical/intel-sdm.html
[2] Intel(R) 64 and IA-32 Architectures Optimization Reference Manual, June 2016.
https://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-optimization-manual.pdf